Tags and Rss
#python
#build-a-blog
Hello and welcome back. I plan to make this the final instalment of this python blog series. After which I am free to write about whatever I like, hooray!
Making my code pretty
At the moment, my code blocks are boring. Sad boring monotone code blocks. So I'm going to add a little flair with some code styling.
I first considered Prism.js, and I gave it a go, but it didn't work instantly, and I decided against sending 18KB of javascript just to do code styling. That's what my build step is for! So I searched for a python option.
And I found it with Pygments! A python library that applies styles to code.
It took a while to get the hang of what it wanted from me, but with the help of this page here: Moonbooks - How to use Markdown and Pygments in Python to enhance the formatting of your content ? I was able to work it out.
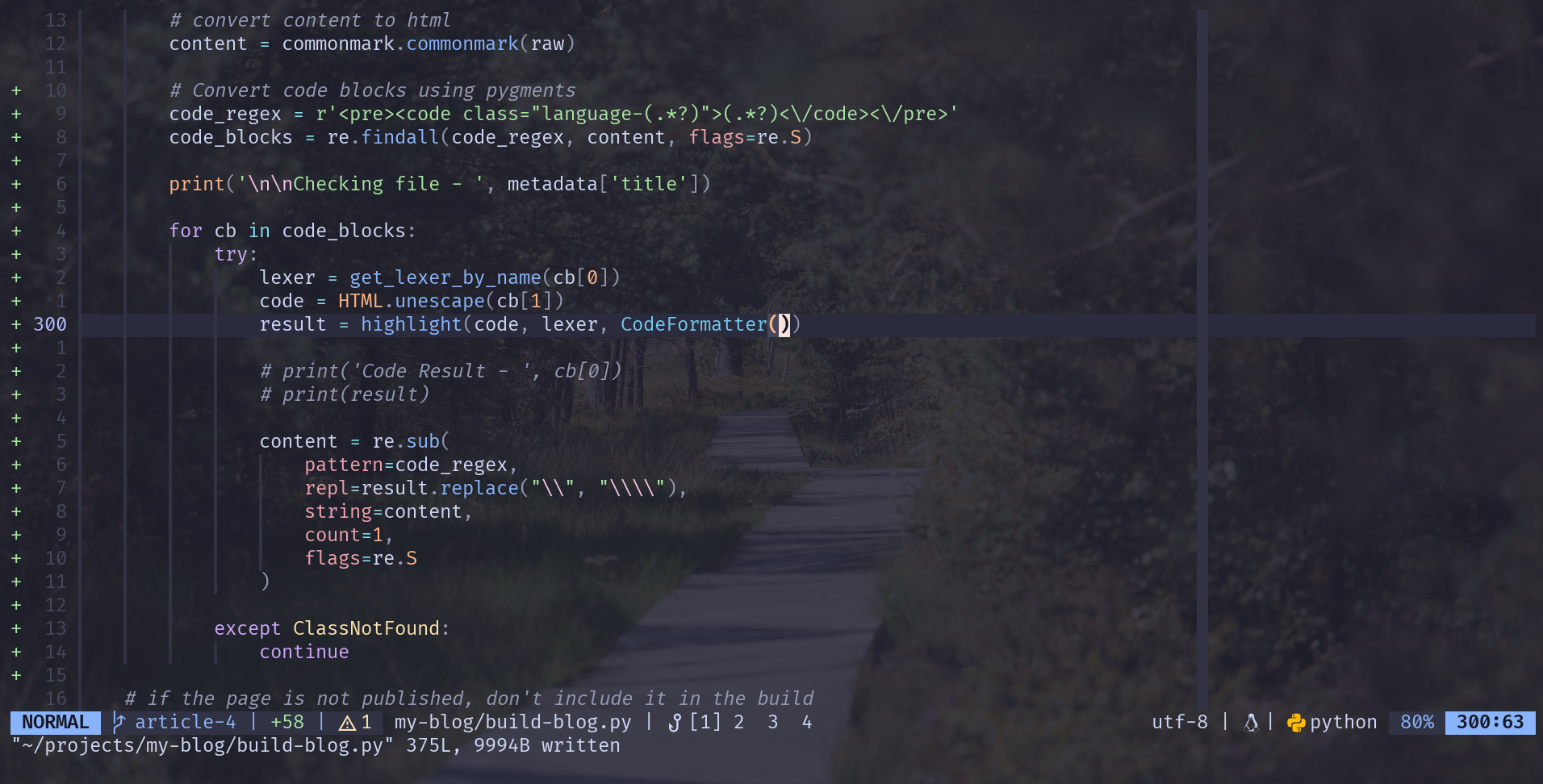
# convert content to html
content = commonmark.commonmark(raw)
+ # Convert code blocks using pygments
+ code_regex = r'<pre><code class="language-(.*?)">(.*?)<\/code><\/pre>'
+ code_blocks = re.findall(code_regex, content, flags=re.S)
+
+
+ for cb in code_blocks:
+ try:
+ lexer = get_lexer_by_name(cb[0])
+ code = HTML.unescape(cb[1])
+ result = highlight(code, lexer, CodeFormatter())
+
+ content = re.sub(
+ pattern=code_regex,
+ repl=result.replace("\\", "\\\\"),
+ string=content,
+ count=1,
+ flags=re.S
+ )
+
+ except ClassNotFound:
+ continue
I added the styling step directly after the markdown processing. I find all of the code blocks with regex, looking for the <pre><code>...</code></pre> tags. I use capture groups to extract the programming language, and the code itself.
For each code block found, I use the language name to get the lexer to parse the code content, and un-escape the code content itself. If the language does not have a lexer, it will throw an error, which I catch and just continue.
Then we run the styling! I mildly extended the default HtmlFormatter() from pygments, to wrap the code with a <code> tag.
Once we have our result, I regex replace the contents, making sure to escape any backslashes.
Now this works, the code blocks get surrounded in spans with classes, but of course I need a style sheet to make anything happen. I played around with having the style sheet generate on build, but I worked out that the sheet doesn't change. So I used the command line API of Pygments to generate the stylesheet, which I placed with the others.
pygmentize -S catppuccin-mocha -f html -a .highlight > code.css
I had to choose a theme, and a quick search revealed that catppuccin had a pygments plugin, so I simply had to choose it. Everyone has a theme they like.
Now, it's not a perfect match to my neovim catppuccin, and I had to edit the css file a little bit, but I think all of my code examples look much better now!
Tags
So, as I plan to begin writing about other various topics, I thought it would be nice to let my (let's be honest, 0) readers know what kind of content would be in a given article. Maybe some people like general dev talk, but don't care about neovim. Or if I ever dip this blog into politics (more when than if), I'm sure some people would want to avoid that like the plague. I can also imagine writing much smaller articles, basically tweets, that could disappoint people that click though expecting more.
So, I'd like to have a list of "tags" shown on links of my articles, and at the top of my articles. Simple enough!
I added a tags entry to the metadata of my Obsidian markdown files. Since these are a YAML list, my normal find / replace method won't work with these.
There's also the index page where I'm writing a loop in the python build script, then moving that into the page, so I think I have to bite the bullet and make...
Loops in templates
Welp, I avoided this for as long as I could, but I really should make my templates a bit smarter. Loops at a minimum, bonus points if I can get condition if - else blocks working too.
I'm going to take some inspiration from Svelte here, and call it an each block. To make things easier, I decided to repeat the key at the start and end of the block.
{{ #each key }}
<!-- each block content -->
{{ /each key }}
With this, I can parse the template using regex, and I don't need to do any open / close counting.
I rewrote my home page link template like so:
<main>
<section class="container">
- <!-- {{ content }} -->
+ {{ #each pages }}
+ <article>
+ <hgroup>
+ <div class="grid">
+ <h4>
+ <a class="contrast" href="/{{ slug }}">
+ {{ title }}
+ </a>
+ </h4>
+ <p class="to-end">{{ publish_date }}</p>
+ </div>
+ <p>
+ <small>
+ {{ description }}
+ </small>
+ </p>
+ </hgroup>
+ <footer>
- <!-- {{ tag_list }} -->
+ {{ #each tags }}
+ <code>#{{ . }}</code>
+ {{ /each tags }}
+ </footer>
+ </article>
+ {{ /each pages }}
</section>
</main>
And to render these blocks, I wrote a each block render function!
def replace_template_each(each_key, data_list, template):
"""replaces a list block"""
each_start = f"{{{{ #each {each_key} }}}}"
each_end = f"{{{{ /each {each_key} }}}}"
regex = fr"{each_start}(.*?){each_end}"
matches = re.search(regex, template, re.S)
each_block = ""
if matches:
each_block = matches.group(1)
else:
return template
content = ""
result = template
for data in data_list:
item = each_block
if isinstance(data, dict):
item = template_replace(data, item)
else:
item = template_replace({'.': data}, item)
content += item + "\n"
#
result = re.sub(regex, content, template, flags=re.S)
return result
Now this works for the each blocks, but unfortunately it leaves the empty blocks behind. And I get the feeling that I'm coming at this problem from the wrong direction. So I think it's time to do a template rewrite.
Rewriting my template engine
Up until now, I've been looping over the pages metadata, or other dictionary, and replacing any tags that are found. But that feels backwards to me now, and I don't think it would play nice with if blocks. So I'm flipping the script, I'm going to scan the template for keys, then replace them with data, or delete it if the data isn't found.
Because the order of operations is highly important, I'll make sure to replace each key in order which they are found in the document.
Through the magic of writing the code before the article, I can now tell you how I rewrote everything!
The entry point is much like my previous, call a function with a dictionary of data, and the template to fill out.
# Article page
html = fill_template(page.metadata, html)
# Home page
html = fill_template(index_data, template['index'])
The fun stuff is inside!
The main loop
Fill template holds the main loop of the templating engine.
def fill_template(data_dict, template):
print('Filling template')
# Get all keys in template
keys = re.findall(r"{{\s*(.*?)\s*}}", template)
result = template
for key in keys:
if key == 'content':
# Content is special, and will be replaced later
continue
if '#if' in key:
result = fill_if(key, data_dict, result)
continue
if '#each' in key:
result = fill_each(key, data_dict, result)
continue
result = fill_data(key, data_dict, result)
return result
First, I use a regex to find all of the tags present in the template. I've improved it slightly, so having white space around the tag doesn't affect it.
i.e. both {{template}} and {{ template }} are valid!
keys = re.findall(r"{{\s*(.*?)\s*}}", template)
Next we enter the loop. It loops through all of the keys it found, ignoring 'content' because that key is special.
for key in keys:
if key == 'content':
# Content is special, and will be replaced later
continue
if '#if' in key:
result = fill_if(key, data_dict, result)
continue
if '#each' in key:
result = fill_each(key, data_dict, result)
continue
result = fill_data(key, data_dict, result)
Say we're replacing a simple key. We'll ignore the #if and #each blocks for now, and have a look at the fill_data function.
def fill_data(key, data_dict, template):
value = data_dict.get(key)
if value is None or isinstance(value, bool) or isinstance(value, list):
return re.sub(
pattern=fr"{{{{\s*{key}\s*}}}}",
repl="",
string=template,
count=1,
)
if isinstance(value, datetime.date):
value = value.strftime("%d %B %Y")
return re.sub(
pattern=fr"{{{{\s*{key}\s*}}}}",
repl=str(value),
string=template,
count=1,
)
First we get the data we need from the dictionary, using the key provided.
value = data_dict.get(key)
We check if the value is some kind of invalid value, like None, a bool or a list. If so, we delete the tag with a regex substitute! It turns the whole tag into empty space
if value is None or isinstance(value, bool) or isinstance(value, list):
return re.sub(
pattern=fr"{{{{\s*{key}\s*}}}}",
repl="",
string=template,
count=1,
)
Another special case, is dates. I want to format them before inserting, so I replace the value variable with the string formatted date.
if isinstance(value, datetime.date):
value = value.strftime("%d %B %Y")
Lastly, I substitute the tag with the value and return it. I stringify it just in case I've screwed up somewhere, I don't want the program to crash.
return re.sub(
pattern=fr"{{{{\s*{key}\s*}}}}",
repl=str(value),
string=template,
count=1,
)
Next, let's have a look at the conditional #if block!
If
Getting if working was actually easier than I expected.
def fill_if(key, data_dict, template):
result = template
condition = key.replace("#if ", "")
value = data_dict.get(condition)
regex = get_block_regex(key)
if value:
result = re.sub(
pattern=regex,
repl=get_match,
string=template,
count=1,
flags=re.S
)
else:
result = re.sub(
pattern=regex,
repl="",
string=template,
count=1,
flags=re.S
)
return result
Since I only need to check if a key exists or not, I literally only check if the #if block key has a value. I get the key I need by stripping away the #if portion of the tag.
I get the regex pattern I need with a function, it looks awful, but that's regex I suppose.
def get_block_regex(key):
"""Returns regex that will match the block, and capture the contents"""
return fr"{{{{\s*{key}\s*}}}}(.*?){{{{\s*/{key[1:]}\s*}}}}"
The above matches the start and end tags of a #if or #each block, and captures the contents, which I will need later!
With that ready, I check the dictionary value for truthiness, and if true, I replace the tag and contents, with just the contents. On false, I replace it with nothing, deleting the whole tag.
Each
Now each, was a little tricky.
def fill_each(key, data_dict, template):
"""Fill out the each block"""
dict_key = key.replace("#each ", "")
value = data_dict.get(dict_key)
regex = get_block_regex(key)
# If the value is not a list, something is wrong, just delete everything
if not isinstance(value, list):
result = re.sub(
pattern=regex,
repl="",
string=template,
count=1,
flags=re.S
)
return result
# Get the contents of the each block, to use as a template
inner_template = re.search(regex, template, flags=re.S).group(1)
content = ""
# Loop through values of the list
for v in value:
# If not a dict, make it a dict with a dot for a key
if not isinstance(v, dict):
v = {'.': v}
# Fill the inner template out with the dictionary
content += fill_template(v, inner_template) + "\n"
# Replace each block with rendered content
result = re.sub(
pattern=regex,
repl=content,
string=template,
count=1,
flags=re.S
)
return result
The key to each, was using recursion. I make sure the value is a list, get the inner template from the each block, and enter a loop. On each iteration of the loop, I fill the template out, using the same function as before.
Because of this, even if I have multiple nested #each blocks, it should all work perfectly.
Once all the replacements are made and concatenated into the content variable, we replace the each block with the content and return.
And that's it! That's the meat of the my templating engine.
What was I doing?... Right, Tags
After all that refactoring, I accomplished my original goal almost by accident. Using the index template I wrote for the first each attempt, upon finishing the rewrite, just works!
So now I can add tags to my markdown files, and they will appear in the link on the home page! I also added them to the article page under the title for good measure.
Onto the next!
RSS
The last thing on my agenda for this blog is rss feed capability. It was surprisingly easy! I had a quick look around, and looked at the rss spec, and came up with this template.
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0">
<channel>
<title>Schwenckenator.dev</title>
<description>Thoughts on personal projects, neovim, languages, and anything else that crosses my mind</description>
<category>Personal blog</category>
<link>https://schwenckenator.dev</link>
<lastBuildDate>{{ build_date }}</lastBuildDate>
{{ #each items }}
<item>
<title>{{ title }}</title>
<description>{{ description }}</description>
<link>https://schwenckenator.dev/{{ slug }}</link>
<pubDate>{{ publish_date }}</pubDate>
<content>{{ article }}</content>
</item>
{{ /each items }}
</channel>
</rss>
Leveraging the power of my new templating system, I made a little addition to the end of the script, similar to the front page build.
# Create RSS file
rss = template['rss-feed']
destination = os.path.join(build_dir, 'rss.xml')
rss_date_format = "%a, %d %b %Y %H:%M:%S %z"
rss_data = {
'build_date': datetime.datetime.now().strftime(rss_date_format),
'items': [],
}
for page in pages:
data = page.metadata
data['article'] = HTML.escape(page.content)
rss_data['items'].append(data)
rss = fill_template(rss_data, template['rss-feed'], rss_date_format)
with open(destination, 'w') as file:
file.write(rss)
print("finished building rss feed")
All I'm doing is gathering the metadata, and the content into a dictionary, and sending it to my template function. It's so good when things just work. I added a little date formatting optional parameter to the function, to handle RSS dates not being what I was using already.
And finally, I added a link to the RSS xml file in my header templates, which you should see above!
What a journey!
That's it! I'm done building this site for a while.
Not to mean I won't write anything here anymore. I've found writing down my little python adventures very motivating, and I've been quite consistent with working on it. That said, I'm looking forward to working on a new project.
Now that I have tags, I'll be able to post more random nonsense here too! That might be fun (for me).
Anyway, if anyone has read this far, thank you!
Until next time,
pona tawa sina a! mi tawa.