Sorting and Linking
#python
#build-a-blog
Welcome back to my series about building this very website!
Early readers, if there are indeed early readers, may have noticed that my homepage currently displays my articles in chronological order. While this is fine when I have two articles, it is less desirable with more articles.
Sorting my articles
So the first order of business for this time, is to reverse the order that articles are displayed in. I'm going to lean on my markdown metadata from last time, and use the publish_date value to order articles in reverse chronological order.
Which is easy enough! First I loop through all of the markdown files, and extract their metadata and content. The code I had from last time was mostly left intact, but I'll do the build operation later.
# A list of pages to save for the index page
pages = []
for f in glob.iglob(f"{source_dir}/**/*.md"):
# Open markdown file
with open(f, 'r') as file:
# extract frontmatter and raw markdown
metadata, raw = frontmatter.parse(file.read())
# convert content to html
content = commonmark.commonmark(raw)
# if the page is not published, don't include it in the build
if not metadata['is_published']:
continue
# Save data in class
page_data = PageData(f, metadata, content)
# Append to pages list
pages.append(page_data)
I also created a small class to hold the data, along with the file path.
class PageData():
"""A data class to hold page data"""
def __init__(self, filepath, metadata, content):
self.filepath = filepath
self.metadata = metadata
self.content = content
Then the sorting magic. The built in sort is usually more than sufficient, especially in cases like this. I provide a lambda function to tell the sort to sort by the PageData's date, and also to reverse it.
# Sort the pages by `publish_date`
pages.sort(key=lambda p: p.metadata['publish_date'], reverse=True)
With that done, the rest of the build goes mostly the same, except I loop over this sorted array rather than the files directly. If you want to know exactly what changes, you're more than welcome to look at the repo on Github and inspect the diff!
Direct links to other articles
Now that I have the articles in the right order, I want to add links at the top & bottom that link to the next article, so people can go to the next thing without having to go back to the home page.
First, I'll need to add a spot for links in the template, like so.
<section class="container">
<h1>{{ title }}</h1>
+ <section>
+ <a href="{{ previous_href }}">← {{ previous_title }}</a>
+ <span style="margin: 0 10px;"> | </span>
+ <a href="{{ next_href }}">{{ next_title }} →</a>
+ </section>
<section>
<em>Published: {{ publish_date }}</em>
</section>
+ <hr>
{{ content }}
</section>
I've added a few new variables here, including the link urls and titles for the previous and next articles. I also added a <hr> just before the article proper starts because I think that looks good.
With the template sorted, I need to make a way to specify the next / previous articles in the page data. I added a little something to the markdown render loop, taking advantage of the metadata which will automatically be rendered by my template function. To do this, I needed to switch the simple for loop into an enumerate loop, which is something new to me!
~ for index, page in enumerate(pages):
#... other code
+ # Prepare other article links
+ if pages[index-1]:
+ prev = pages[index-1]
+ page.metadata['previous_href'] = prev.metadata['slug']
+ page.metadata['previous_title'] = prev.metadata['title']
+ if pages[index+1]:
+ next = pages[index+1]
+ page.metadata['next_href'] = next.metadata['slug']
+ page.metadata['next_title'] = next.metadata['title']
# replace the other handles
html = template_replace(page.metadata, html)
Annnd that broke my script. My javascript brain has failed me again.
So I changed the if statement to check against length, rather than seeing if the element exists. I also forgot that my list is in reverse order (newest first), so I swapped the prev / next around.
# Prepare other article links
if index > 0:
next = pages[index-1]
page.metadata['next_href'] = next.metadata['slug']
page.metadata['next_title'] = next.metadata['title']
if index < len(pages) - 1:
prev = pages[index+1]
page.metadata['previous_href'] = prev.metadata['slug']
page.metadata['previous_title'] = prev.metadata['title']
And the links work! But, it's revealed another problem...
Unused template elements
Once the links were working, I noticed something on the first page.
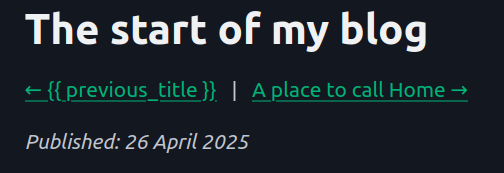
This makes total sense, but it's a bigger problem that it seems. Because the template has these special sections, the simple solution is to check after all substitutions have been made, and delete any remaining template handles. Which would work to get rid of the visible handle.
But the problem I now have with that, is I've put the template content within a <a> tag. Even if I delete the handles, the tag will remain, as will the arrow. I need to find a way to not render the entire tag when there is not a valid link.
My solution, more partials! This link sounds like a kind of component, so I'm going to make a next link partial, and a previous link partial. If this was react or another js framework, I'd bundle them into a single component with logic, but why write smart code when lot dumb code do trick?
The partials look like this
<!-- Previous -->
<a href="{{ href }}">← {{ title }}</a>
<!-- Next -->
<a href="{{ href }}">{{ title }} →</a>
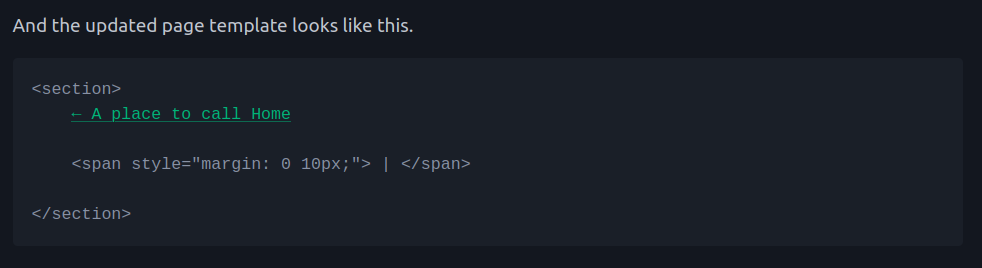
And the updated page template looks like this.
<section>
{{ prev_link }}
<span style="margin: 0 10px;"> | </span>
{{ next_link }}
</section>
Now lets make it actually work. Leaning on the template function I already have, I modified the link building to render the partial, then assign the link metadata the whole tag.
if index > 0:
next = pages[index-1]
link_metadata = {
'href': next.metadata['slug'],
'title': next.metadata['title'],
}
link = template_replace(page.metadata, template['next-link'])
page.metadata['next_link'] = link
With this in place, the template handle if still of course there, but the <a> tag is gone.

Now, I could write some code that deletes any left over handles on finishing. But that seems a bit like magic, and I want this to be a low magic build system. I can foresee pulling my hair out because my template won't render the thing I'm giving it, but I've made a simple spelling mistake. No thanks.
I'm going to explicitly write in a None handler, that returns an empty string to delete the element.
def template_replace(metadata, template):
"""replaces the template placeholder with metadata"""
result = template
for key, value in metadata.items():
print('metadata key - ', key, '; value - ', value)
if value is None:
~ print("It's NONE, deleting the handler")
~ result = result.replace(f"{{{{ {key} }}}}", "")
continue
# ...
Then I use the else blocks of my prev / next checks to assign the metadata link key to None.
if index > 0:
next = pages[index-1]
link_metadata = {
'href': next.metadata['slug'],
'title': next.metadata['title'],
}
link = template_replace(page.metadata, template['next-link'])
page.metadata['next_link'] = link
+ else:
+ # Delete the template handle
+ page.metadata['next_link'] = None
And just like that, the first page's previous link is gone!

Lastly, of course I noticed after I did all this, I used the current page's metadata for the links, instead of the previous / next page's. So all my images have links with the wrong title text. Ah well, this is how real programming works. Simple enough fix, change page.metadata to link_metadata where appropriate.
# Prepare other article links
if index > 0:
next = pages[index-1]
link_metadata = {
'href': next.metadata['slug'],
'title': next.metadata['title'],
}
~ link = template_replace(link_metadata, template['next-link'])
page.metadata['next_link'] = link
else:
# Delete the template handle
page.metadata['next_link'] = None
if index < len(pages) - 1:
prev = pages[index+1]
link_metadata = {
'href': prev.metadata['slug'],
'title': prev.metadata['title'],
}
~ link = template_replace(link_metadata, template['prev-link'])
page.metadata['prev_link'] = link
else:
# Delete the template handle
page.metadata['prev_link'] = None
Fixing the replacement
And now I discover, after checking this article so far, that I have done something very dumb. In the articles content above, my template handlers have been replaced by my function.
In theory it's a simple fix, I just have to replace the content after the other template tags.
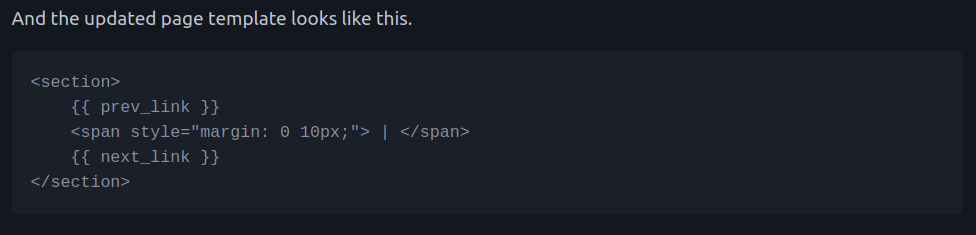
Easy!
Converting Obsidian image link paths
One last thing I've noticed, before I sign off and publish this, is that Obsidian is not currently playing nice with my images. I can have them render in Obsidian, or my built page, but not both. I like writing my articles in Obsidian, so I'm going to add an extra build step for the images, before the markdown is parsed to HTML.
The problem is with file paths. If I write an explicit file path, it will work for the server, but because the articles are written with a different working directory, it doesn't work in Obsidian. So I can add a simple change where all images get modified to have a path to the image file.
I ended up adding this to my file parsing loop, and it works! I now have my images in Obsidian while I'm writing, and in the finished site!
# Open markdown file
with open(f, 'r') as file:
# extract frontmatter and raw markdown
metadata, raw = frontmatter.parse(file.read())
+ # add `/img/` to image urls
+ raw = re.sub(r"!\[(.*)\]\((.*)\)", r"", raw)
# convert content to html
content = commonmark.commonmark(raw)
What's next?
So this blog build system is coming along quite nicely now. I can write all my articles in Obsidian with no cleanup needed for the build output, and I've extended my templating engine to deal with article links. I'm honestly pretty happy with how this is turning out!
I think I have a couple more things I'd like to do before putting this project (but not the blog!) down for a bit. First, I want to include some tags for articles, visible on the home page. As a diversify my articles, I want to make sure the reader knows what they're getting into. And I'd like to build an RSS file, so people that like them can read that way.
Until next time,
pona tawa sina! mi tawa.